
How can Generative AI drive standardisation in the VCM?
Contents
- Data collection using Generative AI
- LLMs for carbon markets
- Barriers to entry
- Scaling transparency in the VCM
The Voluntary Carbon Market (VCM) lacks standardisation in data reporting for carbon credit projects. Registries work in silos and there is limited visibility on how projects move between them. Project documents, such as monitoring reports, are unique to the project and often derived from the bottom-up, structured around elements specific to that project. The lack of standardisation in data reporting is a barrier to scaling the VCM.
Consistent reporting would increase transparency and accountability in the market, and enable benchmarking, comparing, and monitoring of projects by market participants. Generative artificial intelligence (AI) techniques, and Large Language Models (LLMs) in particular, can help us structure this information at a rapid pace.
Non-standardised reporting is driven by a lack of common terminology in the market. This is one of the reasons why BeZero Carbon has made its Carbon Accounting Template (CAT) and data disclosure guidelines public, and why we have invested significant efforts into building an internal domain data model that standardises data for carbon projects, regardless of their registry or offsetting methodology.
Initiatives like the Climate Action Data Trust (CADT) are also working on consistent reporting and monitoring frameworks for the VCM. The VCM will need a standardised data model, or “common language”, to scale the collection and distribution of data across the market.
Developing such frameworks and systems, and driving their adoption across the market, takes time. Even when they are adopted, there is still a wealth of historical information that is only reported in unstructured or semi-structured data formats. By using Generative AI techniques for data collection and standardisation, we can structure and use this information while the VCM moves to more standardised frameworks.
Data collection using Generative AI
2023 has seen LLMs go mainstream, capturing the general public’s imagination. These are machine learning models trained on massive text data sets and show impressive performance on a variety of text classification, summarisation, and generalisation tasks.1 Users typically interact with these models by submitting questions or tasks, called prompts, through a web or application programming interface.
One LLM use case is especially applicable to carbon markets: LLMs excel at taking semi-structured information and transforming them into structured data. At BeZero, we see this application being the greatest value of LLMs will bring to the climate domain.
We are not the first ones to make that observation: researchers at Stanford were able to use such models to achieve state-of-the-art performance on several data cleaning tasks. The same group generalised this to a system that could extract structured information from a large collection of semi-structured documents.2 While some of these approaches are not yet commercially viable (the authors note that deploying their system on a corpus like Wikipedia’s would cost north of $1M), the applicability of LLMs to data parsing and summarisation problems are clear.
LLMs for carbon markets
These advancements suggest Generative AI technology can support the move towards broader standardisation and transparency in the VCM. While production-level use of LLMs does not seem present in the VCM yet, there are signs of experimentation in the market:
Climate Policy Radar has been using natural language processing (NLP) and LLM techniques to make UNFCC climate policy searchable by anyone. The policy team at BeZero has actively been using this tool to inform our policy research since it was launched.
Nika.eco is experimenting with fine-tuning an LLM on carbon offset project documentation and has an impressive demo on their website.
The team at BeZero has been experimenting with LLMs to automate and scale our data collection work. In one instance, we used an LLM to assign a BeZero sector classification to a large sample of projects with high accuracy. We have also successfully applied LLMs for entity extraction tasks based on credit retirements data.
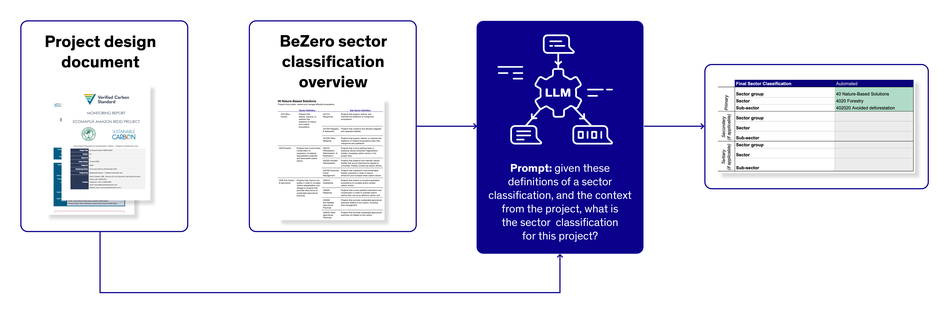
Figure 1: Context derived from project documents can be used to assign a standardised sector classification to a project.
We believe this is only the beginning of a trend in applying LLMs to the VCM and expect their use in the market to grow.
Because unstructured data is abundant in the VCM, LLMs could greatly benefit market participants. They could be used to parse important parameters directly from project documents: for example, the fraction of non-renewable biomass (fNRB) is a key factor in assessing over-crediting risk in cookstove projects, but these measurements are not transparently reported across projects. Extracting these types of fields at scale could help us reliably benchmark such projects.
LLMs’ ability to summarise technical content could also help us with standardising data: carbon offset projects typically prove their efficacy by using so-called ‘additionality tests’.3 These tests are reported in specific sections of a project’s design document, but not in a consistent format. We have found that by employing simple prompts, one can extract and analyse the set of tests used consistently across a range of offset projects.
The size of the text corpus in the VCM domain is also relatively small compared to typical corpora that LLMs are trained and applied on. The four major registries in the VCM collectively list about 4,300 projects that are issuing credits, who have published about 20,000 monitoring reports in total. This makes it easier to train and evaluate an LLM on carbon markets data and means it could be possible to fine-tune a domain specific LLM at reasonable cost. Because LLMs have shown impressive performance on question-answering tasks, a broadly available, fine-tuned LLM on carbon market data may dramatically lower the entry barrier for non-technical users to engage with the domain.
Barriers to entry
There are challenges to deploying LLMs successfully in carbon markets that still need to be worked through, although none of them are specific to carbon markets.
LLMs can fabricate facts and lack causal reasoning ability. Although techniques like re-prompting 4 can reduce fabrications, the risk cannot be eliminated. LLMs also struggle with extracting tabular data, common in carbon offset project reports, and cannot autonomously derive analyses from extracted data. For instance, credit issuance numbers are often inconsistently reported across time periods. Consistently aligning these numbers across different reporting periods seems beyond the capabilities of the current generation of LLMs.
LLMs have a limitation in terms of the amount of text they can process in a single prompt, known as the context window. One can think of the context window as the "working memory" of the LLM, the text it can hold in mind while processing a request. While the number of published documents in the VCM may be relatively small, project documents can still count hundreds of pages, exceeding the length of the typical context window. As a result, how one decides the set of relevant documents, or sections of documents, to include with a prompt matter significantly. Depending on the data extraction task and data inputs, prompting strategies that are tailored to the task are also still a necessity. There is no single approach yet to these problems that consistently works across a range of extraction tasks.
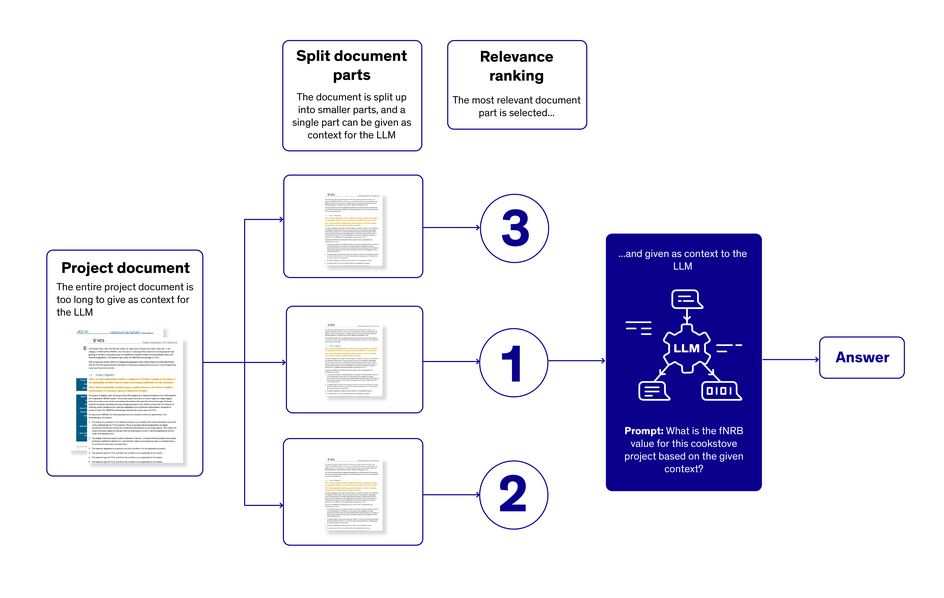
Figure 2: A typical approach to giving extra context to an LLM. The entire project document is too long to give as context, so the document must be split up into parts, and the most relevant part(s) are given as context to the LLM. The way the document is split into parts, and the way the relevance ranking is calculated, dramatically affects the quality of the answer.
Finally, in the context of carbon markets, the carbon footprint of training and operating LLMs cannot be ignored. For instance, it is estimated 5 that just one single training run of GPT-3 by OpenAI has a carbon footprint of 552 tCO2e, the equivalent of more than 2.2 million kilometres driven by an average gasoline-powered passenger vehicle (EPA estimate). Many such training runs will have been carried out in the development of GPT-3 and future model generations. As AI technologies become more prevalent, their carbon impact will grow. Therefore, it's essential to explore sustainable AI development and adoption strategies, such as using energy-efficient hardware and renewable energy sources for data centres.
Scaling transparency in the VCM
Despite these challenges, we are optimistic about the contribution LLMs can make to scaling carbon markets. They can help us extract standardised information from the wealth of historical data already available, and parse new information as projects publish data to the market. Making standardised data readily available in a consumable format could significantly reduce the cost of gathering information. This, in turn, frees up more time for evaluating a project's carbon claims, initiating a virtuous cycle: as a subset of standardised data becomes available, the demand for such data increases, leading to the availability of even more standardised information.
Generative AI techniques are not the solution. The market needs to move towards better and more consistent reporting. But they can help make sense of what is available today and bring some much-needed structure to the information the market is reliant on to scale.
References:
¹ American Carbon Registry, Climate Action Reserve, Gold Standard, and Verra.
² https://arxiv.org/pdf/2304.09433.pdf
³ BeZero Carbon's risk factor series: Additionality